Bradley J. Rhodes MIT Media Lab, E15-305 20 Ames St. Cambridge, MA 02139 rhodes@media.mit.edu Thad Starner MIT Media Lab, E15-394 20 Ames St. Cambridge, MA 02139 thad@media.mit.edu
Published in The Proceedings of The First International Conference on The Practical Application Of Intelligent Agents and Multi Agent Technology (PAAM '96), pp. 487-495.
With more powerful desktop computers, most of a computer's CPU time is spent waiting for the user to hit the next keystroke, read the next page, or load the next packet off the network. There is no reason it can't be using those otherwise wasted CPU cycles constructively by performing continuous searches for information that might be of use in its user's current situation. For example, while an engineer reads email about a project an agent might remind her of project schedules, status reports, and other resources related to the project in question. When she stops reading email and starts editing a file, it should automatically changes it recommendations accordingly.
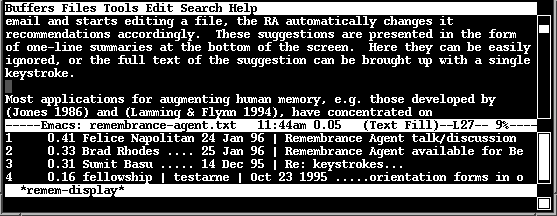
The Remembrance Agent described in this paper performs this continuous, associative form of recall by continuously displaying relevant information which might be relevant to an individual user in their current context. It is designed with the philosophy that, as a continuously running and updating program, it should never distract from the user's primary task, but should instead only augment it. It therefor suggests information sources which may be relevant to the user's current situation in the form of one-line summaries at the bottom of the screen. Here they can be easily monitored, but won't distract from the primary work at hand. The full text of a suggestion can be brought up with a single keystroke.
Fig. 1: A (small) screen-shot of the remembrance-agent in action
Currently, the front-end runs in elisp under Emacs-19, a UNIX based text editor which can also be used for applications such as email, netnews, and web access. It displays one-line suggestions at the bottom of the emacs display buffer, along with a numeric rating indicating how relevant it thinks the document is. These suggestions contain just enough info to relate the contents of the full document being suggested. For example, the suggestion line for a piece of email would contain who the email was from, when it was sent, and its subject-line. A notes file would contain the file-name, date last modified, the first few words of the file, and perhaps the owner of the file. With a simple key combination, the user can bring up the full text of a suggested document. The frequency with which the front end provides new suggestions, the number of suggestions, and whether to look at text notes files, old email, or other document sources is customizable for each user. The user can also customize how much of their current document the RA looks at when creating a suggestion. For example, the top display line may look at the last 500 words when making a suggestion, the two lines at the last 50 words, and the bottom line at the last 10 words. In this way, the RA can be relevant both to the user's overarching context and to any tangent they happen to be on.
The current implementation uses the SMART information retrieval program as a back end, which decides document similarity based on the frequency of words common to the query and reference documents (Salton & Lesk 1971). SMART indexes all the document sources nightly, and also supplies relevant documents based on the "query" text supplied by the front end. While SMART is not as sophisticated as many more modern information-retrieval systems, it has the advantage that it requires no human pre-processing of the documents being indexed.
The RA has been in alpha testing for about three months on a small number of platforms, so usability testing up to this point has been limited to a few users / developers. The beta-test version is now being released to a much larger user-base, so usability test will be starting shortly based both upon user surveys and logs of how often users bring up the full text of a suggestion. However, despite the small numbers of users in the alpha-testing, many lessons have been learned regarding both how the RA should be designed and to what areas it should be applied. These lessons are discussed in the next section.
There are several reasons for this design decision. As stated earlier, systems which only provide information "on request" can't help with associative recall. The user has to know that there is knowledge to be had in a particular situation. The RA therefore needs at least some ability to be proactive in its suggestions. However, unlike the calendar program that warns of upcoming meetings, it is impossible to create a back end which can reliably know when a document is useful for a user. Thus the RA will always suggest many false positives. It is also far less important that a user see an individual suggestion than it is for a calendar program. If the RA only displayed a suggestion when the relevance passed a certain threshold, the users' attention would be drawn away from their primary task whenever a new suggestion appeared. With the high ratio of false-positives, this would rapidly become a prohibitive distraction.
For these reasons the RA's suggestions are kept unobtrusive. There should be no (or at least minimal) cost to the user to see a suggestion and ignore it if deemed not useful at the time. Suggestions are therefore kept to a single line each, and are always printed at the bottom of the text-editor window. The full display area is also limited to a maximum of 9 lines, though it defaults to operating with only three or four. Finally, no color cues or highlights were used in the suggestion-display area, and the suggestions are only changed every 10 seconds or so to further avoid distraction from the primary task. However, suggestions must also pack enough information to allow users to judge their usefulness quickly. Especially important is a date field, as the age of a document is often the best indicator of whether it is useful in a given situation. In some cases, the description line supplies desired information directly without ever needing the full document. For example, it might provide the spelling of the last name of someone who recently sent email.
While suggestions are unobtrusive, it must be trivial both to access the entirety of a suggested document and to return to the primary document once the new one has been viewed. Anecdotal evidence suggests that any more than a second or two delay in bringing up a document is a serious barrier to regular use. In the current implementation, "control-c" and the display line-number brings up the suggested document. It is similarly easy to get back to the primary document.
Using the system has shown that suggestions are much more useful when the document being suggested only contains one "nugget" of information, and when that nugget is clearly displayed on its one-line description. This "less is more" approach solves several problems. First, it allows the user to tell what a suggestion contains from its description without having to peruse the entire document. Second, a document with only one primary point is more likely to be a good hit. Documents which address several issues will rarely match the user's situation exactly, but will often partially match. Finally, if a suggested document is read, the shorter it is the quicker the user can get on with their primary work. Email and short notes files seem to be a very good length for RA suggestions. In future versions of the RA, longer documents will be broken up into pieces during indexing so that a suggestion can relate to a particular piece.
Personal email and notes files are a good source of documents for other reasons as well. Most importantly, they are both pre-personalized to the individual user and automatically change as the user's interest changes. This is one of the more important features of the RA, because it means that through proper choice of data to index the RA automatically adapts to the individual user. This guarantees that the pool of suggestions is much richer in potentially interesting information than, for example, the Web, and also helps solve many synonym problems. For example, when an AI researcher mentions "agents" in a paper, that person's RA will suggest work on autonomous agents. A chemist's RA, on the other hand, will bring up lists of various solvents and other chemical agents.
Some of the future applications discussed in the next section require using non-personalized indexes, which is analogous to using another person's memory. However, there are disadvantages beyond those discussed above. For example, it is harder to judge the content of a suggestion from its one-line summary when the user is less familiar with it. The user might also not be able to properly judge the validity of an unfamiliar suggestion. For example, they might not know that a set of instructions were made in jest, or were in a subsequent message shown to be incorrect. Similarly, documentation or lectures geared towards one kind of audience may be inappropriate for another, so it helps when the original context is well understood. Finally, there are privacy issues when using someone else's memories. Even if one accesses someone's email files with express permission, the people who sent that person mail might not have approved.
W. Cohen, 1996. Learning Rules that Classify E-mail, in AAAI Spring Symposium on Machine Learning in Information Access, Stanford, CA, March 1996.
D. Harman (Ed.). (1995). The Third Text REtrieval Conference (TREC-3). National Institute of Standards and Technology Special Publication 500-225, Gaithersburg, Md. 20899.
K. Hammond, R. Burke, and K. Schmitt, 1994. A Case-Based Approach to Knowledge Navigation, in Working Papers of the AAAI Workshop on multi-media and artificial intelligence, July 1994.
HotWired. http://www.hotwired.com/
W. Jones, 1986. On the Applied Use of Human Memory Models: the Memory Extender Personal Filing System. The International Journal of Man-Machine Studies 25, 191-228
M. Lamming and M. Flynn, 1994. " Forget-me-not:" Intimate Computing in Support of Human Memory. In Proceedings of FRIEND21, '94 International Symposium on Next Generation Human Interface, Meguro Gajoen, Japan.
K. Lang, 1995. NewsWeeder: Learning to filter netnews, in Machine Learning: Proceedings of the Twelfth International Conference, Lake Taho, CA, 1995.
H. Lieberman, Letizia: An Agent That Assists Web Browsing, International Joint Conference on Artificial Intelligence, Montreal, August 1995.
P. Maes, 1994. Agents that Reduce Work and Information Overload. Communications of the ACM 37(7):30-40.
M. Mauldin and J. Leavitt, 1994. Web Agent Related Research at the Center for Machine Translation. Presented at the SIGNIDR meeting, August 4, 1994, McLean, Virginia. http://www.lycos.com/
G. Salton, ed. 1971. The SMART Retrieval System -- Experiments in Automatic Document Processing. Englewood Cliffs, NJ: Prentice-Hall, Inc.
T. Starner, S. Mann, B. Rhodes, J. Healey, K. Russell, J. Levine, and A. Pentland, 1995. Wearable Computing and Augmented Reality, Technical Report, Media Lab Vision and Modeling Group RT-355, MIT
C. Wickens, 1992. Engineering Psychology and Human Performance. Scott Foresman Little Brown.